SLM vs LLM: Why Small Language Models Are Winning Enterprise AI in 2026
SLM vs LLM: Why Small Language Models Are Winning Enterprise AI in 2026
There is a quiet revolution happening in enterprise AI, and it has nothing to do with bigger models. While headlines chase the next trillion-parameter breakthrough, the companies actually deploying AI at scale are moving in the opposite direction — toward smaller, task-specific models that run on hardware they own.
The data backs this up. According to Gartner, by 2027 organizations will use small task-specific AI models three times more than general-purpose LLMs (Gartner Press Release, April 2025). Domain-specific GenAI deployments are projected to reach 50% of enterprise implementations by 2027, up from just 1% in 2023 — a 50x shift in four years.
Here is what the data says, and what we have seen firsthand deploying AI for European SMEs.
flowchart TD
A[New AI Task] --> B{Task Complexity?}
B -->|Routine, repetitive| C[Small Language Model]
B -->|Complex, novel| D{Data Sensitivity?}
D -->|Sensitive / GDPR| E[Local LLM]
D -->|Non-sensitive| F[Cloud LLM API]
C --> G[Local Hardware]
E --> G
F --> H[Cloud Provider]
G --> I[EUR 0 per query]
H --> J[EUR 0.01-0.10 per query]
style C fill:#059669,color:#fff
style E fill:#2563EB,color:#fff
style F fill:#D97706,color:#fff
style G fill:#0D9488,color:#fffWhat Are SLMs and Why Do They Matter?
Small Language Models (SLMs) typically range from 1 to 30 billion parameters. Think Gemma 2 9B, Phi-4, Mistral Small 24B, or Llama 3 8B. They are trained on curated, often domain-specific data and optimized to excel at particular tasks rather than doing everything.
Large Language Models (LLMs) — GPT-4, Claude, Llama 3 70B — have broader knowledge, stronger reasoning, and handle novel or complex queries better. But that generality comes with a cost: compute, latency, and often, a cloud dependency that conflicts with European data sovereignty requirements.
The Cost Reality: Local SLM vs Cloud LLM
This is where the conversation gets concrete. Here is what we see in real client deployments:
| Factor | SLM (Local, e.g. Gemma 2 9B) | LLM (Cloud API, e.g. GPT-4o) |
|---|---|---|
| Cost per 1M tokens | ~EUR 0.05 (electricity only) | EUR 2.50 - 15.00 |
| GPU RAM required | 8-28 GB (runs on Mac Mini M4) | Cloud-hosted |
| Latency | 15-40ms local | 200-800ms network |
| Data residency | On-premise, GDPR compliant | Third-party cloud |
| Monthly cost (moderate use) | ~EUR 30 electricity | EUR 200-2,000+ |
| Break-even vs cloud | 3-5 months | Ongoing expense |
For context: Llama 3 8B needs 27.8 GB of GPU RAM, while Llama 3 70B requires 160 GB — a 5.7x difference that determines whether you need a EUR 700 Mac Mini or a EUR 15,000 GPU server.
Gartner also projects that inference costs for 1-trillion-parameter LLMs will drop 90% by 2030 compared to 2025 (Gartner, 2025). But for most enterprise tasks, you do not need to wait — SLMs already deliver comparable results at a fraction of the cost today.
For a deeper analysis of the numbers, see our Cloud vs Local AI Cost Analysis.
When to Use an SLM vs an LLM: Decision Guide
Not every task needs a 70B model. Not every task can be handled by a 9B one. Here is how we help clients decide:
| Use Case | Recommended | Why |
|---|---|---|
| Customer support triage | SLM | Repetitive, structured, high-volume |
| Document classification | SLM | Pattern matching, domain-specific labels |
| Internal knowledge Q&A | SLM + RAG | Retrieval-augmented, bounded domain |
| Email drafting / templates | SLM | Consistent tone, predictable output |
| Complex legal analysis | LLM | Nuanced reasoning, broad knowledge needed |
| Novel research synthesis | LLM | Cross-domain connections, creativity |
| Code generation (production) | LLM | Accuracy-critical, wide context |
| Data extraction from invoices | SLM | Structured output, high volume, fine-tunable |
The pattern is clear: high-frequency, routine tasks go to SLMs; complex, novel tasks go to LLMs. Most enterprise workloads — 70-80% by our estimate — fall into the first category.
The Hybrid Approach: Best of Both Worlds
The smartest enterprises in 2026 are not choosing one or the other. They are building routing layers that send each query to the right-sized model.
This is the architecture we deploy for our clients:
- Incoming request classification — A lightweight model (or simple rules) determines task complexity
- SLM handles routine work — Document processing, classification, templated responses, data extraction
- LLM escalation for edge cases — When the SLM’s confidence drops below a threshold, or the task requires multi-step reasoning, it routes to a cloud LLM
- RAG + fine-tuning bridges the gap — With retrieval-augmented generation and domain fine-tuning, SLMs perform like LLMs for specific verticals
In practice, this means 80% of queries never leave the client’s hardware, and the 20% that do go to a cloud LLM are genuinely the ones that benefit from it. The result: lower costs, faster responses, and full GDPR compliance for the bulk of operations.
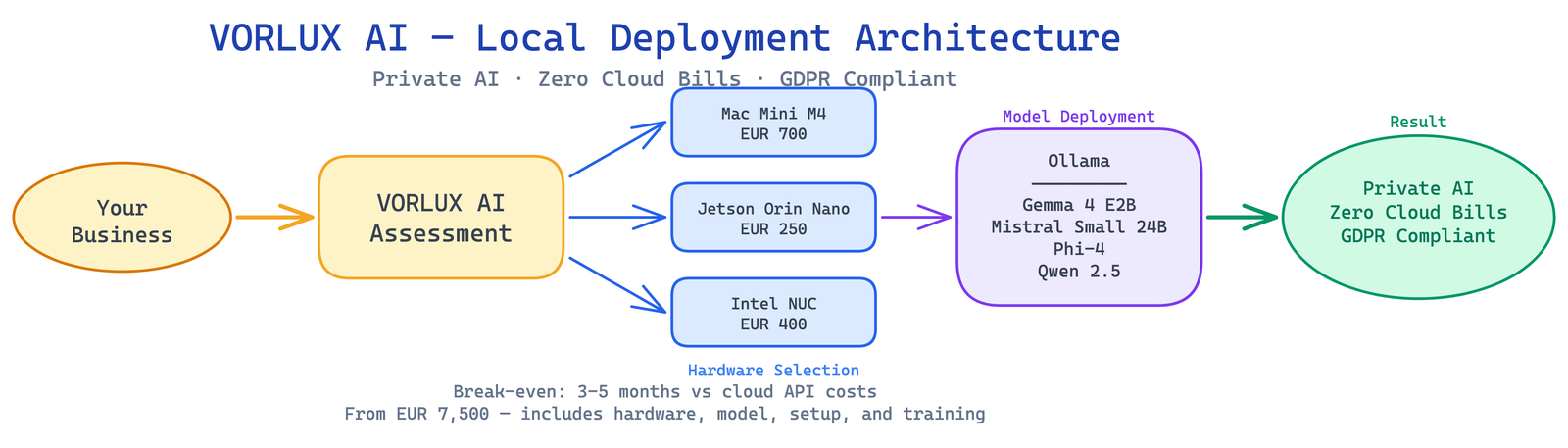
We run this exact stack for European SMEs using models like Gemma 2 9B, Phi-4, and Mistral Small 24B on Mac Mini M4 hardware. Clients typically break even against cloud API costs within 3 to 5 months. For model benchmarks and recommendations, see our Best Local LLM Models Q2 2026 Comparison.
What This Means for Your Business
The shift toward SLMs is not a technical curiosity — it is a strategic inflection point. Companies that deploy the right-sized model for each task will spend less, move faster, and maintain control over their data.
If you are evaluating AI deployment for your organization, the question is no longer “which LLM should we use?” It is “which tasks can we handle locally, and which genuinely need cloud-scale reasoning?”
That is exactly the analysis we do at VORLUX AI. We help European businesses map their AI workloads, select the right model size for each task, and deploy locally where it makes sense. Learn more about our Edge AI deployment services.
Ready to find the right model size for your business? Book a free consultation and we will analyze your workloads, estimate your cost savings, and design a hybrid architecture that fits your budget and compliance requirements.
Sources: Gartner Top Trends Shaping AI Strategies, April 2025 | AI Magazine | Computer Weekly
Related reading
- Best Local LLM Models for Q2 2026: Practical Comparison for SMEs
- AESIA: What Every Spanish Business Deploying AI Must Know in 2026
- AI Evaluations: How to Test Your RAG Pipeline Before Going Live
Ready to Get Started?
VORLUX AI helps Spanish and European businesses deploy AI solutions that stay on your hardware, under your control. Whether you need edge AI deployment, LMS integration, or EU AI Act compliance consulting — we can help.
Book a free discovery call to discuss your AI strategy, or explore our services to see how we work.